
A LibAFL Introductory Workshop
Intro
Why LibAFL
Fuzzing is great! Throwing randomized inputs at a target really fast can have unreasonable effectiveness with the right setup. When starting with a new target a fuzzing harness can iterate along with your reversing/auditing efforts and you can sleep well at night knowing your cores are taking the night watch. When looking for bugs our time is often limited; any effort spent on tooling needs to be time well spent. LibAFL is a great library that can let us quickly adapt a fuzzer to our specific target. Not every target fits nicely into the "Command-line program that parses a file" category, so LibAFL lets us craft fuzzers for our specific situations. This adaptability opens up the power of fuzzing for a wider range of targets.
Why a workshop
The following material comes from an internal workshop used as an introduction to LibAFL. This post is a summary of the workshop, and includes a repository of exercises and examples for following along at home. It expects some existing understanding of rust and fuzzing concepts. (If you need a refresher on rust: google's comprehensive rust is great.)
There are already a few good resources for learning about LibAFL.
- The "LibAFL Book" was created by a few of the LibAFL maintainers, and is a wonderful resource. https://aflplus.plus/libafl-book/
- epi has a great series of posts that delve into the creation of a few example fuzzers using LibAFL. https://epi052.gitlab.io/notes-to-self/blog/2021-11-01-fuzzing-101-with-libafl/
- The LibAFL repository itself contains a number of useful examples that can be a reference for your own fuzzers. https://github.com/AFLplusplus/LibAFL/tree/main/fuzzers
This workshop seeks to add to the existing corpus of example fuzzers built with LibAFL, with a focus on customizing fuzzers to our targets. You will also find a few starter problems for getting hands on experience with LibAFL. Throughout the workshop we try to highlight the versatility and power of the library, letting you see where you can fit a fuzzer in your flow.
Course Teaser
As an aside, if you are interested in this kind of thing (security tooling, bugs, fuzzing), you may be interested in our Symbolic Execution course. We have a virtual session planned for Febuary 2024 with ringzer0. There is more information at the end of this post.
The Fuzzers
The target
Throughout the workshop we beat up on a simple target that runs on Linux. This target is not very interesting, but acts as a good example target for our fuzzers. It takes in some text, line by line, and replaces certain identifiers (like {{XXd3sMRBIGGGz5b2}}) with names. To do so, it contains a function with a very large lookup tree. In this function many lookup cases can result in a segmentation fault.
//...
const char* uid_to_name(const char* uid) {
/*...*/ // big nested mess of switch statements
switch (nbuf[14]) {
case 'b':
// regular case, no segfault
addr = &names[0x4b9];
LOG("UID matches known name at %p", addr);
return *addr;
/*...*/
case '7':
// a bad case
addr = ((const char**)0x68c2);
// SEGFAULT here
LOG("UID matches known name at %p", addr);
return *addr;
/*...*/This gives us a target that has many diverting code paths, and many reachable "bugs" to find. As we progress we will adapt our fuzzers to this target, showing off some common ways we can mold a fuzzer to a target with LibAFL.
You can find our target here, and the repository includes a couple variations that will be useful for later examples. ./fuzz_target/target.c
Pieces of a Fuzzer
Before we dive into the examples, let's establish an quick understanding of modern fuzzer internals. LibAFL breaks a fuzzer down into pieces that can be swapped out or changed. LibAFL makes great use of rust's trait system to do this. Below we have a diagram of a very simple fuzzer.

A block diagram of a minimal fuzzer
The script for this fuzzer could be as simple as the following.
while ! [ -f ./core.* ]
do
head -c 900 /dev/urandom > ./testfile
cat ./testfile | ./target
doneThe simple fuzzer above follows three core steps.
1) Makes a randomized input
2) Runs the target with the new input
3) Keeps the created input if it causes a "win" (in this case a win is crash that produces a core file)
If you miss any of the above pieces, you won't have a very good fuzzer. We all have heard the sad tale of researchers who piped random inputs into their target, got an exciting crash, but were unable to ever reproduce the bug because they didn't save off the test case.
Even with the above pieces, that simple fuzzer will struggle to make any real progress toward finding bugs. It does not even have a notion of what progress means! Below we have a diagram of what a more modern fuzzer might look like.
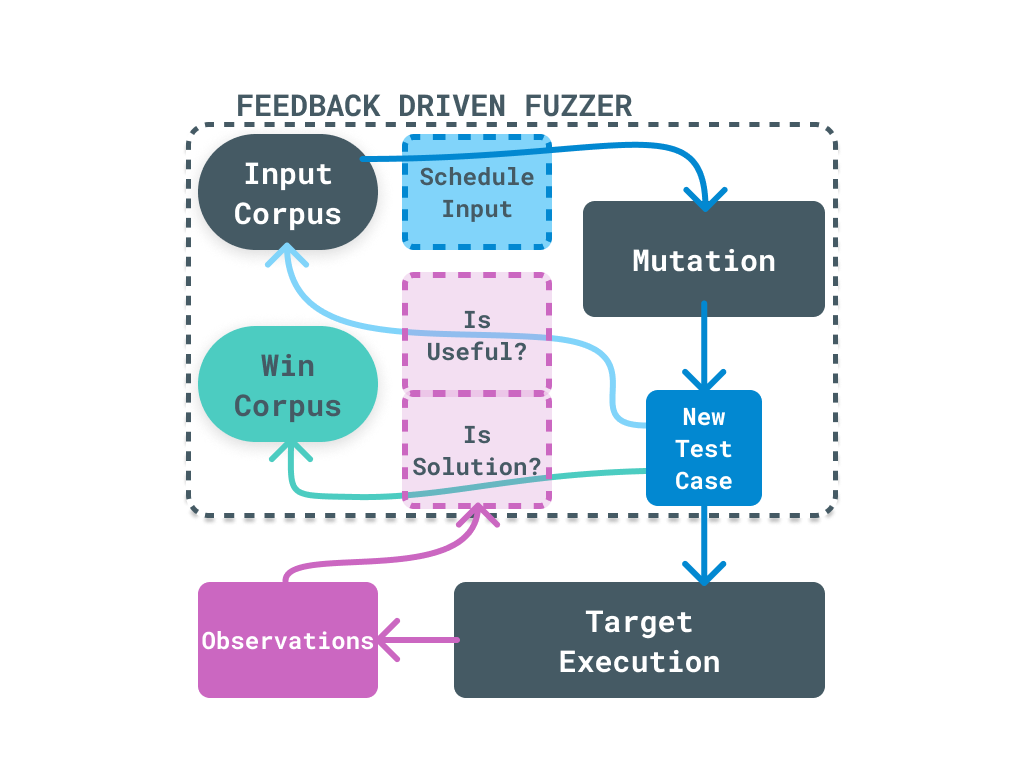
A block diagram of a fuzzer with feedback
This fuzzer works off a set of existing inputs, which are randomly mutated to create the new test cases. The "mutations" are just a simple set of modifications to the input that can be quickly applied to generate new exciting inputs. Importantly, this fuzzer also uses observations from the executing target to know if a inputs was "interesting". Instead of only caring out crashes, a fuzzer with feedback can route mutated test cases back into the set of inputs to be mutated. This allows a fuzzer to progress by iterating on an input, tracking down interesting features in the target.
LibAFL provides tools for each of these "pieces" of a fuzzer.
- Implementors of the
Executortrait will run a target with a given test case. - The
Corpustrait is for items that hold a collection of test cases, usually for inputs or solutions. - Something implementing the
Schedulertrait is in charge of selecting inputs from a corpus to make the next test cases. - The
Mutatortrait implementors provide the modifications to change an input before a run. - The
FeedbackandObservertraits provide useful tools for deciding if an input was useful.
There are other important traits we will see as well. Be sure to look at the "Implementors" section of the trait documentation to see useful implementations provided by the library.
Exec fuzzer
Which brings us to our first example! Let's walk through a bare-bones fuzzer using LibAFL.
The source is well-commented, and you should read through it. Here we just highlight a few key sections of this simple fuzzer.
//...
let mut executor = CommandExecutor::builder()
.program("../fuzz_target/target")
.build(tuple_list!())
.unwrap();
let mut state = StdState::new(
StdRand::with_seed(current_nanos()),
InMemoryCorpus::<BytesInput>::new(),
OnDiskCorpus::new(PathBuf::from("./solutions")).unwrap(),
&mut feedback,
&mut objective,
).unwrap();Our fuzzer uses a "state" object which tracks the set of input test cases, any solution test cases, and other metadata. Notice we are choosing to keep our inputs in memory, but save out the solution test cases to disk.
We use a CommandExecutor for executing our target program, which will run the target process and pass in the test case.
//...
let mutator = StdScheduledMutator::with_max_stack_pow(
havoc_mutations(),
9, // maximum mutation iterations
);
let mut stages = tuple_list!(StdMutationalStage::new(mutator));We build a very simple pipeline for our inputs. This pipeline only has one stage, which will randomly select from a set of mutations for each test case.
//...
let scheduler = RandScheduler::new();
let mut fuzzer = StdFuzzer::new(scheduler, feedback, objective);
// load the initial corpus in our state
// since we lack feedback in this fuzzer, we have to force this,
state.load_initial_inputs_forced(&mut fuzzer, &mut executor, &mut mgr, &[PathBuf::from("../fuzz_target/corpus/")]).unwrap();
// fuzz
fuzzer.fuzz_loop(&mut stages, &mut executor, &mut state, &mut mgr).expect("Error in fuzz loop");With a fuzzer built from a scheduler and some feedbacks (here we use a ConstFeedback::False to not have any feedback except for the objective feedback which is a CrashFeedback), we can load our initial entries and start to fuzz. We use the created stages, chosen executor, the state, and an event manager to start fuzzing. Our event manager will let us know when we start to get "wins".
[jordan exec_fuzzer]$ ./target/release/exec_fuzzer/
[Testcase #0] run time: 0h-0m-0s, clients: 1, corpus: 1, objectives: 0, executions: 1, exec/sec: 0.000
[Testcase #0] run time: 0h-0m-0s, clients: 1, corpus: 2, objectives: 0, executions: 2, exec/sec: 0.000
[Testcase #0] run time: 0h-0m-0s, clients: 1, corpus: 3, objectives: 0, executions: 3, exec/sec: 0.000
[Objective #0] run time: 0h-0m-1s, clients: 1, corpus: 3, objectives: 1, executions: 3, exec/sec: 2.932
[Stats #0] run time: 0h-0m-15s, clients: 1, corpus: 3, objectives: 1, executions: 38863, exec/sec: 2.590k
[Objective #0] run time: 0h-0m-20s, clients: 1, corpus: 3, objectives: 2, executions: 38863, exec/sec: 1.885k
...Our fragile target quickly starts giving us crashes, even with no feedback. Working from a small set of useful inputs helps our mutations be able to find crashing inputs.
This simple execution fuzzer gives us a good base to work from as we add features to our fuzzer.
Exec fuzzer with custom feedback
We can't effectively iterate on interesting inputs without feedback. Currently our random mutations must generate a crashing case in one go. If we can add feedback to our fuzzer, then we can identify test cases that did something interesting. We will loop those interesting test cases back into our set of cases for further mutation.
There are many different sources we could turn to for this information. For this example, let's use the fuzz_target/target_dbg binary which is a build of our target with some debug output on stderr. By looking at this debug output we can start to identify interesting cases. If a test case gets us some debug output we hadn't previously seen before, then we can say it is interesting and worth iterating on.
There isn't an existing implementation of this kind of feedback in the LibAFL library, so we will have to make our own! If you want to try this yourself, we have provided a template file in the repository.
./exec_fuzzer_stderr_template/
The LibAFL repo provides a StdErrObserver structure we can use with our CommandExecutor. This observer will allow our custom feedback structure to receive the stderr output from our run. All we need to do is create a structure that implements the is_interesting method of the Feedback trait, and we should be good to go. In that method we are provided with the state, the mutated input, the observers. We just have to get the debug output from the StdErrObserver and determine if we reached somewhere new.
impl<S> Feedback<S> for NewOutputFeedback
where
S: UsesInput + HasClientPerfMonitor,
{
fn is_interesting<EM, OT>(
&mut self,
_state: &mut S,
_manager: &mut EM,
_input: &S::Input,
observers: &OT,
_exit_kind: &ExitKind
) -> Result<bool, Error>
where EM: EventFirer<State = S>,
OT: ObserversTuple<S>
{
// return Ok(false) for uninteresting inputs
// return Ok(true) for interesting ones
Ok(false)
}
}I encourage you to try implementing this feedback yourself. You may want to find some heuristics to ignore unhelpful debug messages. We want to avoid reporting too many inputs as useful, so we don't overfill our input corpus. The input corpus is the set of inputs we use for generating new test cases. We will waste lots of time when there are inputs in that set that are not actually helping us dig towards a win. Ideally we want each of these inputs to be as small and quick to run as possible, while exercising a unique path in our target.
In our solution, we simply keep a set of seen hashes. We report an input to be interesting if we see it caused a unique hash.
./exec_fuzzer_stderr/src/main.rs
//...
fn is_interesting<EM, OT>(
&mut self,
_state: &mut S,
_manager: &mut EM,
_input: &S::Input,
observers: &OT,
_exit_kind: &ExitKind
) -> Result<bool, Error>
where EM: EventFirer<State = S>,
OT: ObserversTuple<S>
{
let observer = observers.match_name::<StdErrObserver>(&self.observer_name)
.expect("A NewOutputFeedback needs a StdErrObserver");
let mut hasher = DefaultHasher::new();
hasher.write(&observer.stderr.clone().unwrap());
let hash = hasher.finish();
if self.hash_set.contains(&hash) {
Ok(false)
} else {
self.hash_set.insert(hash);
Ok(true)
}
}This ends up finding "interesting" inputs very quickly, and blowing up our input corpus.
...
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 308, objectives: 0, executions: 4388, exec/sec: 2.520k
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 309, objectives: 0, executions: 4423, exec/sec: 2.520k
[Objective #0] run time: 0h-0m-1s, clients: 1, corpus: 309, objectives: 1, executions: 4423, exec/sec: 2.497k
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 310, objectives: 1, executions: 4532, exec/sec: 2.520k
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 311, objectives: 1, executions: 4629, exec/sec: 2.521k
...Code Coverage Feedback
Relying on the normal side-effects of a program (like debug output, system interactions, etc) is not very reliable for deeply exploring a target. There may be many interesting features that we miss using this kind of feedback. The feedback of choice for many modern fuzzers is "code coverage". By observing what blocks of code are being executed, we can gain insight into what inputs are exposing interesting logic.
Being able to collect that information, however, is not always straight forward. If you have access to the source code, you may be able to use a compiler to instrument the code with this information. If not, you may have to find ways to dynamically instrument your target either through binary modification, emulation, or other sources.
AFL++ provides a version of clang with compiler-level instrumentation for providing code coverage feedback. LibAFL can observe the information produced by this instrumentation, and we can use it for feedback. We have a build of our target using afl-clang-fast. With this build (target_instrumented), we can use the LibAFL ForkserverExecutor to communicate with our instrumented target. The HitcountsMapObserver can use shared memory for receiving our coverage information each run.
You can see our fuzzer's code here.
//...
let mut shmem_provider = UnixShMemProvider::new().unwrap();
let mut shmem = shmem_provider.new_shmem(MAP_SIZE).unwrap();
// write the id to the env var for the forkserver
shmem.write_to_env("__AFL_SHM_ID").unwrap();
let shmembuf = shmem.as_mut_slice();
// build an observer based on that buffer shared with the target
let edges_observer = unsafe {HitcountsMapObserver::new(StdMapObserver::new("shared_mem", shmembuf))};
// use that observed coverage to feedback based on obtaining maximum coverage
let mut feedback = MaxMapFeedback::tracking(&edges_observer, true, false);
// This time we can use a fork server executor, which uses a instrumented in fork server
// it gets a greater number of execs per sec by not having to init the process for each run
let mut executor = ForkserverExecutor::builder()
.program("../fuzz_target/target_instrumented")
.shmem_provider(&mut shmem_provider)
.coverage_map_size(MAP_SIZE)
.build(tuple_list!(edges_observer))
.unwrap();The compiled-in fork server should also reduce our time needed to instantiate a run, by forking off partially instantiated processes instead of starting from scratch each time. This should offset some of the cost of our instrumentation.
When executed, our fuzzer quickly finds new paths through the process, building up our corpus of interesting cases and guiding our fuzzer.
[jordan aflcc_fuzzer]$ ./target/release/aflcc_fuzzer
[Stats #0] run time: 0h-0m-0s, clients: 1, corpus: 0, objectives: 0, executions: 0, exec/sec: 0.000
[Testcase #0] run time: 0h-0m-0s, clients: 1, corpus: 1, objectives: 0, executions: 1, exec/sec: 0.000
[Stats #0] run time: 0h-0m-0s, clients: 1, corpus: 1, objectives: 0, executions: 1, exec/sec: 0.000
[Testcase #0] run time: 0h-0m-0s, clients: 1, corpus: 2, objectives: 0, executions: 2, exec/sec: 0.000
[Stats #0] run time: 0h-0m-0s, clients: 1, corpus: 2, objectives: 0, executions: 2, exec/sec: 0.000
...
[Testcase #0] run time: 0h-0m-10s, clients: 1, corpus: 100, objectives: 0, executions: 19152, exec/sec: 1.823k
[Objective #0] run time: 0h-0m-10s, clients: 1, corpus: 100, objectives: 1, executions: 19152, exec/sec: 1.762k
[Stats #0] run time: 0h-0m-11s, clients: 1, corpus: 100, objectives: 1, executions: 19152, exec/sec: 1.723k
[Testcase #0] run time: 0h-0m-11s, clients: 1, corpus: 101, objectives: 1, executions: 20250, exec/sec: 1.821k
...Custom Mutation
So far we have been using the havoc_mutations, which you can see here is a set of mutations that are pretty good for lots of targets.
Many of these mutations are wasteful for our target. In order to get to the vulnerable uid_to_name function, the input must first pass a valid_uid check. In this check, characters outside of the range A-Za-z0-9\-_ are rejected. Many of the havoc_mutations, such as the BytesRandInsertMutator, will introduce characters that are not in this range. This results in many test cases that are wasted.
With this knowledge about our target, we can use a custom mutator that will insert new bytes only in the desired range. Implementing the Mutator trait is simple, we just have to provide a mutate function.
//...
impl<I, S> Mutator<I, S> for AlphaByteSwapMutator
where
I: HasBytesVec,
S: HasRand,
{
fn mutate(
&mut self,
state: &mut S,
input: &mut I,
_stage_idx: i32,
) -> Result<MutationResult, Error> {
/*
return Ok(MutationResult::Mutated) when you mutate the input
or Ok(MutationResult::Skipped) when you don't
*/
Ok(MutationResult::Skipped)
}
}If you want to try this for yourself, feel free to use the aflcc_custom_mut_template as a template to get started.
In our solution we use a set of mutators, including our new AlphaByteSwapMutator and a few existing mutators. This set should hopefully result in a greater number of valid test cases that make it to the uid_to_name function.
//...
// we will specify our custom mutator, as well as two other helpful mutators for growing or shrinking
let mutator = StdScheduledMutator::with_max_stack_pow(
tuple_list!(
AlphaByteSwapMutator::new(),
BytesDeleteMutator::new(),
BytesInsertMutator::new(),
),
9,
);Then in our mutator we use the state's source of random to choose a location, and a new byte from a set of valid characters.
//...
fn mutate(
&mut self,
state: &mut S,
input: &mut I,
_stage_idx: i32,
) -> Result<MutationResult, Error> {
// here we apply our random mutation
// for our target, simply swapping a byte should be effective
// so long as our new byte is 0-9A-Za-z or '-' or '_'
// skip empty inputs
if input.bytes().is_empty() {
return Ok(MutationResult::Skipped)
}
// choose a random byte
let byte: &mut u8 = state.rand_mut().choose(input.bytes_mut());
// don't replace tag chars '{{}}'
if *byte == b'{' || *byte == b'}' {
return Ok(MutationResult::Skipped)
}
// now we can replace that byte with a known good byte
*byte = *state.rand_mut().choose(&self.good_bytes);
// technically we should say "skipped" if we replaced a byte with itself, but this is fine for now
Ok(MutationResult::Mutated)
}And that is it! The custom mutator works seamlessly with the rest of the system. Being able to quickly tweak fuzzers like this is great for adapting to your target. Experiments like this can help us quickly iterate when combined with performance measurements.
...
[Stats #0] run time: 0h-0m-1s, clients: 1, corpus: 76, objectives: 1, executions: 2339, exec/sec: 1.895k
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 77, objectives: 1, executions: 2386, exec/sec: 1.933k
[Stats #0] run time: 0h-0m-1s, clients: 1, corpus: 77, objectives: 1, executions: 2386, exec/sec: 1.928k
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 78, objectives: 1, executions: 2392, exec/sec: 1.933k
...Example Problem
At this point, we have a separate target you may want to experiment with! It is a program that contains a small maze, and gives you a chance to create a fuzzer with some custom feedback or mutations to better traverse the maze and discover a crash. Play around with some of the concepts we have introduced here, and see how fast your fuzzer can solve the maze.
[jordan maze_target]$ ./maze -p
██████████████
█.██......█ ██
█....██ █.☺ █
██████ █ ██ █
██ ██████ █
█ █ █ ██
█ ███ ██████
█ ███ ██ ██
██ ███ █ █
████ ██ ███ █
█ █ ██ █ █
█ ████ ███ █ █
█ █
████████████
Found:
############
# #
# # ### #### #
# # ## #...@#
# ### ##.####
# # ###...##
## ## ###..#
######...###.#
##.....#..#..#
#..######...##
#.##.# ######
#....# ##....#
## #......##.#
[Testcase #0] run time: 0h-0m-2s, clients: 1, corpus: 49, objectives: 0, executions: 5745, exec/sec: 2.585k
Found:
############
# #
# # ### ####@#
# # ## #....#
# ### ##.####
# # ###...##
## ## ###..#
######...###.#
##.....#..#..#
#..######...##
#.##.# ######
#....# ##....#
## #......##.#
[Testcase #0] run time: 0h-0m-3s, clients: 1, corpus: 50, objectives: 0, executions: 8892, exec/sec: 2.587kGoing Faster
Persistent Fuzzer
In previous examples, we have made use of the ForkserverExecutor which works with the forkserver that afl-clang-fast inserted into our target. While the fork server does give us a great speed boost by reducing the start-up time for each target process, we still require a new process for each test case. If we can instead run multiple test cases in one process, we can speed up our fuzzing greatly. Running multiple testcases per target process is often called "persistent mode" fuzzing.
As they say in the AFL++ documentation:
Basically, if you do not fuzz a target in persistent mode, then you are just doing it for a hobby and not professionally :-).
Some targets do not play well with persistent mode. Anything that changes lots of global state each run can have trouble, as we want each test case to run in isolation as much as possible. Even for targets well suited for persistent mode, we usually will have to create a harness around the target code. This harness is just a bit of code we write to call in to the target for fuzzing. The AFL++ documentation on persistent mode with LLVM is a great reference for writing these kinds of harnesses.
When we have created such a harness, the inserted fork server will detect the ability to persist, and can even use shared memory to provide the test cases. LibAFL's ForkserverExecutor can let us make use of these persistent harnesses.
Our fuzzer using a persistent harness is not much changed from our previous fuzzers.
./persistent_fuzzer/src/main.rs
The main change is in telling our ForkServerExecutor that it is_persistent(true).
//...
let mut executor = ForkserverExecutor::builder()
.program("../fuzz_target/target_persistent")
.is_persistent(true)
.shmem_provider(&mut shmem_provider)
.coverage_map_size(MAP_SIZE)
.build(tuple_list!(edges_observer))
.unwrap();The ForkserverExecutor takes care of the magic to make this all happen. Most of our work goes into actually creating an effective harness! If you want to try and craft your own, we have a bit of a template ready for you to get started.
./fuzz_target/target_persistent_template.c
In our harness we want to be careful to reset state each round, so we remain as true to our original as possible. Any modified global variables, heap allocations, or side-effects from a run that could change the behavior of future runs needs to be undone. Failure to clean the program state can result in false positives or instability. If we want our winning test cases from this fuzzer to also be able to crash the original target, then we need to emulate the original target's behavior as close as possible.
Sometimes it is not worth it to emulate the original, and instead use our harness to target deeper surface. For example in our target we could directly target the uid_to_name function, and then convert the solutions into solutions for our original target later. We would want to also call valid_uid in our harness, to ensure we don't report false positives that would never work against our original target.
You can inspect our persistent harness here; we choose to repeatedly call process_line for each line and take care to clean up after ourselves.
./fuzz_target/target_persistent.c
Where previously we saw around 2k executions per second for our fuzzers with code coverage feedback, we are now seeing around 5k or 6k, still with just one client.
[Stats #0] run time: 0h-0m-16s, clients: 1, corpus: 171, objectives: 4, executions: 95677, exec/sec: 5.826k
[Testcase #0] run time: 0h-0m-16s, clients: 1, corpus: 172, objectives: 4, executions: 96236, exec/sec: 5.860k
[Stats #0] run time: 0h-0m-16s, clients: 1, corpus: 172, objectives: 4, executions: 96236, exec/sec: 5.821k
[Testcase #0] run time: 0h-0m-16s, clients: 1, corpus: 173, objectives: 4, executions: 96933, exec/sec: 5.863k
[Stats #0] run time: 0h-0m-16s, clients: 1, corpus: 173, objectives: 4, executions: 96933, exec/sec: 5.798k
[Testcase #0] run time: 0h-0m-16s, clients: 1, corpus: 174, objectives: 4, executions: 98077, exec/sec: 5.866k
[Stats #0] run time: 0h-0m-16s, clients: 1, corpus: 174, objectives: 4, executions: 98077, exec/sec: 5.855k
[Testcase #0] run time: 0h-0m-16s, clients: 1, corpus: 175, objectives: 4, executions: 98283, exec/sec: 5.867k
[Stats #0] run time: 0h-0m-16s, clients: 1, corpus: 175, objectives: 4, executions: 98283, exec/sec: 5.853k
[Testcase #0] run time: 0h-0m-16s, clients: 1, corpus: 176, objectives: 4, executions: 98488, exec/sec: 5.866kIn-Process Fuzzer
Using AFL++'s compiler and fork server is not the only way to achieve multiple test cases in one process. LibAFL is an extremely flexible library, and supports all sorts of scenarios. The InProcessExecutor allows us to run test cases directly in the same process as our fuzzing logic. This means if we can link with our target somehow, we can fuzz in the same process.
The versatility of LibAFL means we can build our entire fuzzer as a library, which we can link into our target, or even preload into our target dynamically. LibAFL even supports nostd (compilation without dependency on an OS or standard library), so we can treat our entire fuzzer as a blob to inject into our target's environment. As long as execution reaches our fuzzing code, we can fuzz.
In our example we build our fuzzer and link with our target built as a static library, calling into the C code directly using rust's FFI.
Building our fuzzer and causing it to link with our target is done by providing a build.rs file, which the rust compilation will use.
//...
fn main() {
let target_dir = "../fuzz_target".to_string();
let target_lib = "target_libfuzzer".to_string();
// force us to link with the file 'libtarget_libfuzzer.a'
println!("cargo:rustc-link-search=native={}", &target_dir);
println!("cargo:rustc-link-lib=static:+whole-archive={}", &target_lib);
println!("cargo:rerun-if-changed=build.rs");
}LibAFL also provides tools to wrap the clang compiler, if you wish to create a compiler that will automatically inject your fuzzer into the target. You can see examples of this in the LibAFL examples.
We will want a harness for this target as well, so we can pass our test cases in as a buffer instead of having the target read lines from stdin. We will use the common interface used by libfuzzer, which has us create a function called LLVMFuzzerTestOneInput. LibAFL even has some helpers that will do the FFI calls for us.
Our harness can be very similar to the one we created for persistent mode fuzzing. We also have to watch out for the same kinds of global state or memory leaks that could make our fuzzing unstable. Again, we have a template for you if you want to craft the harness yourself.
./fuzz_target/target_libfuzzer_template.c
With LLVMFuzzerTestOneInput defined in our target, and a static library made, our fuzzer can directly call into the harness for each test case. We define a harness function which our executor will call with the test case data.
//...
// our executor will be just a wrapper around a harness
// that calls out the the libfuzzer style harness
let mut harness = |input: &BytesInput| {
let target = input.target_bytes();
let buf = target.as_slice();
// this is just some niceness to call the libfuzzer C function
// but we don't need to use a libfuzzer harness to do inproc fuzzing
// we can call whatever function we want in a harness, as long as it is linked
libfuzzer_test_one_input(buf);
return ExitKind::Ok;
};
let mut executor = InProcessExecutor::new(
&mut harness,
tuple_list!(edges_observer),
&mut fuzzer,
&mut state,
&mut restarting_mgr,
).unwrap();This easy interoperability with libfuzzer harnesses is nice, and again we see a huge speed improvement over our previous fuzzers.
[jordan inproc_fuzzer]$ ./target/release/inproc_fuzzer
Starting up
[Stats #1] (GLOBAL) run time: 0h-0m-16s, clients: 2, corpus: 0, objectives: 0, executions: 0, exec/sec: 0.000
(CLIENT) corpus: 0, objectives: 0, executions: 0, exec/sec: 0.000, edges: 0/37494 (0%)
...
[Testcase #1] (GLOBAL) run time: 0h-0m-19s, clients: 2, corpus: 102, objectives: 5, executions: 106146, exec/sec: 30.79k
(CLIENT) corpus: 102, objectives: 5, executions: 106146, exec/sec: 30.79k, edges: 136/37494 (0%)
[Stats #1] (GLOBAL) run time: 0h-0m-19s, clients: 2, corpus: 102, objectives: 5, executions: 106146, exec/sec: 30.75k
(CLIENT) corpus: 102, objectives: 5, executions: 106146, exec/sec: 30.75k, edges: 137/37494 (0%)
[Testcase #1] (GLOBAL) run time: 0h-0m-19s, clients: 2, corpus: 103, objectives: 5, executions: 106626, exec/sec: 30.88k
(CLIENT) corpus: 103, objectives: 5, executions: 106626, exec/sec: 30.88k, edges: 137/37494 (0%)
[Objective #1] (GLOBAL) run time: 0h-0m-20s, clients: 2, corpus: 103, objectives: 6, executions: 106626, exec/sec: 28.32k
...In this fuzzer we are also making use of a very important tool offered by LibAFL: the Low Level Message Passing (LLMP). This provides quick communication between multiple clients and lets us effectively scale our fuzzing to multiple cores or even multiple machines. The setup_restarting_mgr_std helper function creates an event manager that will manage the clients and restart them when they encounter crashes.
//...
let monitor = MultiMonitor::new(|s| println!("{s}"));
println!("Starting up");
// we use a restarting manager which will restart
// our process each time it crashes
// this will set up a host manager, and we will have to start the other processes
let (state, mut restarting_mgr) = setup_restarting_mgr_std(monitor, 1337, EventConfig::from_name("default"))
.expect("Failed to setup the restarter!");
// only clients will return from the above call
println!("We are a client!");This speed gain is important, and can make the difference between finding the juicy bug or not. Plus, it feels good to use all your cores and heat up your room a bit in the winter.
Emulation
Of course, not all targets are so easy to nicely link with or instrument with a compiler. In those cases, LibAFL provides a number of interesting tools like libafl_frida or libafl_nyx. In this next example we are going to use LibAFL's modified version of QEMU to give us code coverage feedback on a binary with no built in instrumentation. The modified version of QEMU will expose code coverage information to our fuzzer for feedback.
The setup will be similar to our in-process fuzzer, except now our harness will be in charge of running the emulator at the desired location in the target. By default the emulator state is not reset for you, and you will want to reset any global state changed between runs.
If you want to try it out for yourself, consult the Emulator documentation, and feel free to start with our template.
In our solution we first execute some initialization until a breakpoint, then save off the stack and return address. We will have to reset the stack each run, and put a breakpoint on the return address so that we can stop after our call. We also map an area in our target where we can place our input.
//...
emu.set_breakpoint(mainptr);
unsafe { emu.run() };
let pc: GuestReg = emu.read_reg(Regs::Pc).unwrap();
emu.remove_breakpoint(mainptr);
// save the ret addr, so we can use it and stop
let retaddr: GuestAddr = emu.read_return_address().unwrap();
emu.set_breakpoint(retaddr);
let savedsp: GuestAddr = emu.read_reg(Regs::Sp).unwrap();
// now let's map an area in the target we will use for the input.
let inputaddr = emu.map_private(0, 0x1000, MmapPerms::ReadWrite).unwrap();
println!("Input page @ {inputaddr:#x}");Now in the harness itself we will take the input and write it into the target, then start execution at the target function. This time we are executing the uid_to_name function directly, and using a mutator that will not add any invalid characters that valid_uid would have stopped.
//...
let mut harness = |input: &BytesInput| {
let target = input.target_bytes();
let mut buf = target.as_slice();
let mut len = buf.len();
// limit out input size
if len > 1024 {
buf = &buf[0..1024];
len = 1024;
}
// write our testcase into memory, null terminated
unsafe {
emu.write_mem(inputaddr, buf);
emu.write_mem(inputaddr + (len as u64), b"\0\0\0\0");
};
// reset the registers as needed
emu.write_reg(Regs::Pc, parseptr).unwrap();
emu.write_reg(Regs::Sp, savedsp).unwrap();
emu.write_return_address(retaddr).unwrap();
emu.write_reg(Regs::Rdi, inputaddr).unwrap();
// run until our breakpoint at the return address
// or a crash
unsafe { emu.run() };
// if we didn't crash, we are okay
ExitKind::Ok
};This emulation can be very quick, especially if we can get away without having to reset a lot of state each run. By targeting a deeper function here we are likely to reach crashes quickly.
...
[Stats #0] run time: 0h-0m-1s, clients: 1, corpus: 54, objectives: 0, executions: 33349, exec/sec: 31.56k
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 55, objectives: 0, executions: 34717, exec/sec: 32.85k
[Stats #0] run time: 0h-0m-1s, clients: 1, corpus: 55, objectives: 0, executions: 34717, exec/sec: 31.59k
[Testcase #0] run time: 0h-0m-1s, clients: 1, corpus: 56, objectives: 0, executions: 36124, exec/sec: 32.87k
[2023-11-25T20:24:02Z ERROR libafl::executors::inprocess::unix_signal_handler] Crashed with SIGSEGV
[2023-11-25T20:24:02Z ERROR libafl::executors::inprocess::unix_signal_handler] Child crashed!
[Objective #0] run time: 0h-0m-1s, clients: 1, corpus: 56, objectives: 1, executions: 36124, exec/sec: 28.73k
...LibAFL also provides some useful helpers such as QemuAsanHelper and QemuSnapshotHelper. There is even support for full system emulation, as opposed to usermode emulation. Being able to use emulators effectively when fuzzing opens up a whole new world of targets.
Generation
Our method of starting with some initial inputs and simply mutating them can be very effective for certain targets, but less so for more complicated inputs. If we start with an input of some javascript like:
if (a < b) {
somefunc(a);
}Our existing mutations might result in the following:
if\x00 (a << b) {
somefu(a;;;;
}Which might find some bugs in parsers, but is unlikely to find deeper bugs in any javascript engine. If we want to exercise the engine itself, we will want to mostly produce valid javascript. This is a good use case for generation! By defining a grammar of what valid javascript looks like, we can generate lots of test cases to throw against the engine.

A block diagram of a basic generative fuzzer
As you can see in the diagram above, with just generation alone we are no longer using a mutation+feedback loop. There are lots of successful fuzzers that have gotten wins off generation alone (domato, boofuzz, a bunch of weird midi files), but we would like to have some form of feedback and progress in our fuzzing.
In order to make use of feedback in our generation, we can create an intermediate representation (IR) of our generated data. Then we can feed back the interesting cases into our inputs to be further mutated.
So our earlier javascript could be expressed as tokens like:
(if
(cond_lt (var a), (var b)),
(code_block
(func_call some_func,
(arg_list (var a))
)
)
)Our mutations on this tokenized version can do things like replace tokens with other valid tokens or add more nodes to the tree, creating a slightly different input. We can then use these IR inputs and mutations as we did earlier with code coverage feedback.

A block diagram of a generative fuzzer with mutation feedback
Now mutations on the IR could produce something like so:
(if
(cond_lt (const 0), (var b)),
(code_block
(func_call some_func
(arg_list
(func_call some_func,
(arg_list ((var a), (var a)))
)
)
)
)
)Which would render to valid javascript, and can be further mutated upon if it produces interesting feedback.
if (0 < b) {
somefunc(somefunc(a,a));
}LibAFL provides some great tools for getting your own generational fuzzer with feedback going. A version of the Nautilus fuzzer is included in LibAFL. To use it with our example, we first define a grammar describing what a valid input to our target looks like.
./aflcc_custom_gen/grammar.json
With LibAFL we can load this grammar into a NautilusContext that we can use for generation. We use a InProcessExecutor and in our harness we take in a NautilusInput which we render to bytes and pass to our LLVMFuzzerTestOneInput.
./aflcc_custom_gen/src/main.rs
//...
// our executor will be just a wrapper around a harness closure
let mut harness = |input: &NautilusInput| {
// we need to convert our input from a natilus tree
// into actual bytes
input.unparse(&genctx, &mut bytes);
let s = std::str::from_utf8(&bytes).unwrap();
println!("Trying:\n{:?}", s);
let buf = bytes.as_mut_slice();
libfuzzer_test_one_input(&buf);
return ExitKind::Ok;
};We also need to generate a few initial IR inputs and specify what mutations to use.
//...
if state.must_load_initial_inputs() {
// instead of loading from an inital corpus, we will generate our initial corpus of 9 NautilusInputs
let mut generator = NautilusGenerator::new(&genctx);
state.generate_initial_inputs_forced(&mut fuzzer, &mut executor, &mut generator, &mut restarting_mgr, 9).unwrap();
println!("Created initial inputs");
}
// we can't use normal byte mutations, so we use mutations that work on our generator trees
let mutator = StdScheduledMutator::with_max_stack_pow(
tuple_list!(
NautilusRandomMutator::new(&genctx),
NautilusRandomMutator::new(&genctx),
NautilusRandomMutator::new(&genctx),
NautilusRecursionMutator::new(&genctx),
NautilusSpliceMutator::new(&genctx),
NautilusSpliceMutator::new(&genctx),
),
3,
);With this all in place, we can run and get the combined benefits of generation, code coverage, and in-process execution. To iterate on this, we can further improve our grammar as we better understand our target.
//...
(CLIENT) corpus: 145, objectives: 2, executions: 40968, exec/sec: 1.800k, edges: 167/37494 (0%)
[Testcase #1] (GLOBAL) run time: 0h-0m-26s, clients: 2, corpus: 146, objectives: 2, executions: 41229, exec/sec: 1.811k
(CLIENT) corpus: 146, objectives: 2, executions: 41229, exec/sec: 1.811k, edges: 167/37494 (0%)
[Objective #1] (GLOBAL) run time: 0h-0m-26s, clients: 2, corpus: 146, objectives: 3, executions: 41229, exec/sec: 1.780k
(CLIENT) corpus: 146, objectives: 3, executions: 41229, exec/sec: 1.780k, edges: 167/37494 (0%)
[Stats #1] (GLOBAL) run time: 0h-0m-27s, clients: 2, corpus: 146, objectives: 3, executions: 41229, exec/sec: 1.755kNote that our saved solutions are just serialized NautilusInputs and will not work when used against our original target. We have created a separate project that will render these solutions out to bytes with our grammar.
./gen_solution_render/src/main.rs
//...
let input: NautilusInput = NautilusInput::from_file(path).unwrap();
let mut b = vec![];
let tree_depth = 0x45;
let genctx = NautilusContext::from_file(tree_depth, grammarpath);
input.unparse(&genctx, &mut b);
let s = std::str::from_utf8(&b).unwrap();
println!("{s}");[jordan gen_solution_render]$ ./target/release/gen_solution_render ../aflcc_custom_gen/solutions/id\:0
bar{{PLvkLizOcGccywcS}}foo
{{EGgkWs-PxeqpwBZK}}foo
bar{{hlNeoKiwMTNfqO_h}}
[jordan gen_solution_render]$ ./target/release/gen_solution_render ../aflcc_custom_gen/solutions/id\:0 | ../fuzz_target/target
Segmentation fault (core dumped)Example Problem 2
This brings us to our second take home problem! We have a chat client that is vulnerable to a number of issues. Fuzzing this binary could be made easier though good use of generation and/or emulation. As you find some noisy bugs you may wish to either avoid those paths in your fuzzer, or patch the bugs in your target. Bugs can often mask other bugs. You can find the target here.
As well as one example solution that can fuzz the chat client.
-- Ping from 16937944: D�DAAAATt'AAAAPt'%222�%%%%%%9999'pRR9&&&%%%%%2Tt�{�''pRt�'%99999999'pRR9&&&&&&999AATt'%&'pRt�'%TTTTTTTTTTTTTT9999999'a%''AAA��TTt�'% --
-- Error sending message: Bad file descriptor --
[Stats #0] run time: 0h-0m-5s, clients: 1, corpus: 531, objectives: 13, executions: 26752, exec/sec: 0.000
[Testcase #0] run time: 0h-0m-5s, clients: 1, corpus: 532, objectives: 13, executions: 26760, exec/sec: 0.000
-- Ping from 16937944: D�DAAAATT'%'aRt�'%9999'pRR����������T'%'LLLLLLLLLLLa%'nnnnnmnnnT'AA''��'A�'%'p%''A9999'pRR����������'pRR��R�� --
[2023-11-25T21:29:19Z ERROR libafl::executors::inprocess::unix_signal_handler] Crashed with SIGSEGV
[2023-11-25T21:29:19Z ERROR libafl::executors::inprocess::unix_signal_handler] Child crashed!Conclusion
The goal of this workshop is to show the versatility of LibAFL and encourage its use. Hopefully these examples have sparked some ideas of how you can encorporate custom fuzzers against some of your targets. Let us know if you have any questions or spot any issues with our examples. Alternately, if you have an interesting target and want us to find bugs in it for you, please contact us.
Course Plug
Thanks again for reading! If you like this kind of stuff, you may be interested in our course "Practical Symbolic Execution for VR and RE" where you will learn to create your own symbolic execution harnesses for: reverse engineering, deobfuscation, vulnerability detection, exploit development, and more. The next public offering is in Febuary 2024 as part of ringzer0's BOOTSTRAP24. We are also available for private offerings on request.
More info here. https://ringzer0.training/trainings/practical-symbolic-execution.html